How to make your robot go from A to B without hitting things (Pt. 1)

Aug 10, 2017
To use a robot, you need to be able to plan a path from point A to point B — bonus points for not hitting anything. This is the cornerstone of our roadmap for robotics. Here’s a quick overview of the different ways to achieve this.
As discussed in the OMPL primer, there are different families of planning algorithms. In this first post we’ll focus on sampling-based planning.
Sampling-based planning: OMPL
OMPL is the de facto open source planning library. It’s tightly integrated in ROS and MoveIt! Before going any further, let me introduce a few words to keep things clear:
- Workspace: the physical space in which the robot can operate — the region we are exploring to find a path.

- State space: all the different possible configurations of the robot. A configuration is called a state.

- Free state space: the collision free states in the state space.

OMPL is a sampling-based motion planning library: a number of states are generated, the states in collision are pruned. This gives us a sampling of the free state space. The subset of this free state space which best solves our problem — going from A to B — is then selected.


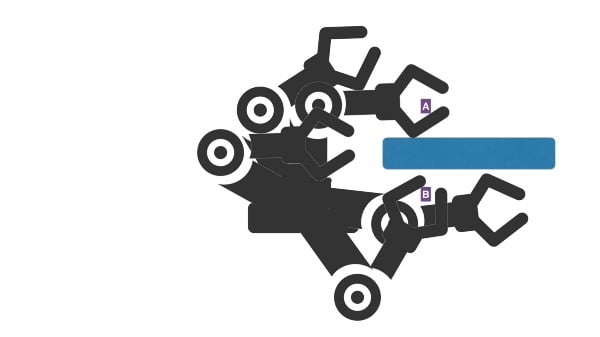
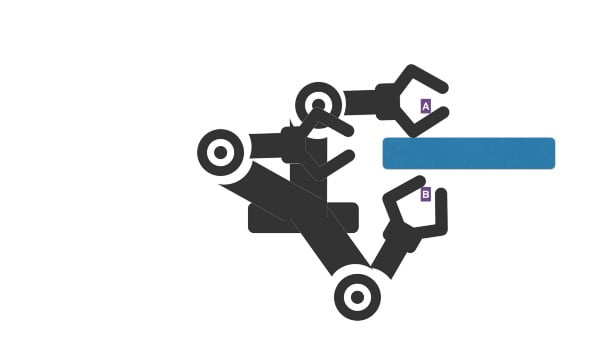
top: keep only free state space / bottom: select best candidates to solve the plan from the free state space.
The difference between the planners in OMPL are the heuristic with which the state space is generated and the way the state space is sampled to identify the states that’ll compose the plan.
Probabilistic Roadmap (PRM)
The PRM algorithms populate the whole workspace with uniformly spaced state spaces. Once the colliding states are pruned to get the free state space, each state is connected to its closest neighbour — if the path between the two states is also collision free — this gives us a graph of connected states.
Once we have that graph, searching for the quickest path between the start state and the goal is a common problem to solve.
Tree-Based Planners (RRT, EST, SBL, KPiece…)
For the tree-based planners, the exploration of the space is using trees (either starting from the start state, the goal state, or both). The main difference with PRM is that we do not have cycles in our graph, making the problem solving more efficient.

I hope this post has given you an overview explaining how path planning works. We’ll be following up soon with a second post about control-based path planners. If you have any questions so far, feel free to tweet us @ShadowRobot, or the author of this post, our Chief Technical Architect @UgoCupcic.